前置知识
注释符
-
--+(推荐使用)在GET请求中,+会被解析为空格,常用于URL注入 -
#(需URL编码)在GET请求中需编码为%23,避免与前端锚点冲突 -
/**/(多行注释)用于绕过空格过滤,可代替空格分隔SQL关键字在实践,当上面的注释符不可用时,还可以尝试
%00或闭合的形式绕过
LIKE语句和转义字符
LIKE语句
再MySQL中LIKE语句用于模糊查询,其基本格式就是
|
|
例如在一堆数据中查询包含@的数据
|
|
但是因为一些字符的特殊性导致like语句的参数并不全都是'%\匹配目标%'那么简单,
例如你要查询含有\的数据,参数就要填'%\\\\%',详情见下文。
转义字符对照表
| 转义序列 | 代表的字符 | 说明 |
|---|---|---|
\n |
换行符(LF) | 表示换行操作 |
\t |
制表符(Tab) | 表示横向制表 |
\r |
回车符(CR) | 表示回车操作 |
\b |
退格符 | 表示删除前一个字符的操作 |
\0 |
NULL 字符 | ASCII 0 字符,常用于字符串结束标记 |
\\ |
反斜杠 \ |
表示反斜杠本身(字符串中直接写\会被解析为转义符,需用 \\表示字面量) |
\' |
单引号 ' |
表示单引号本身(避免与字符串的单引号边界冲突) |
\" |
双引号 " |
表示双引号本身(当 SQL 模式为ANSI_QUOTES时,双引号可能被解析为标识符,需转义) |
在 LIKE 查询中,%和_是通配符,若要匹配它们本身,必须额外转义。
| 目标字符 | 转义方式(默认) | 转义方式(ESCAPE 自定义) | 示例(默认转义) |
|---|---|---|---|
%(百分号) |
\% |
#%(以 #为转义符) |
LIKE '%\%%' |
_(下划线) |
\_ |
#_(以 #为转义符) |
LIKE '%\_%' |
\(反斜杠) |
\\\\ |
#\(以 #为转义符) |
LIKE '%\\\\%' |
🔍 注意:
- 反斜杠只转义紧跟其后的一个字符,所以
\%只会把后面的%转义为普通字符,不会影响其他字符。 - 在 LIKE 中,反斜杠本身需要 双重转义 (
\\\\),因为 MySQL 会先解析一次\\为\,然后 LIKE 再解析一次\\为\,最终得到一个字面量\。
ORDER BY与联合查询注入
这一部分在之前的文章已有讲述,详见1.5 mysql注入初步
仅补充一下注入测试位置

报错注入
报错注入指利用错误信息回显获取数据库内容
适用于页面无法正常回显查询内容,但会详细显示查询过程的错误信息时,可通过构造特殊SQL语句触发错误,将想要查询的数据通过错误信息带出。
✅标准注入方法是(以单引号闭合为例):
|
|
方法一:XPath函数报错
updatexml函数的定义
updatexml()函数用于修改XML文档中的节点。
|
|
第一个参数XML_document是XML文档对象的名称。
第二个参数XPath_string是指定需要更新的XML节点的XPath表达式。
第三个参数new_value是新值,用于替换找到的符合条件的数据。
如果XPath_string格式错误,MySQL会抛出一个XPath语法错误。
updatexml报错注入
|
|

updatexml()函数的报错就是在第二参数上做文章,这里的concat(0x7e,version(),0x7e)试图通过concat()函数拼接一个字符串,version()函数返回当前数据库的名称。但是0x7e是一个十六进制值,代表的是ASCII字符~,通常不直接用于XPath表达式,这导致二个参数的XPath表达式格式不正确,引发函数报错。
所以这里只要在concat()函数中构造我们要查询的SQL注入Payload就可以利用:
爆数据库版本信息:
|
|
爆当前数据库名:
|
|
爆当前库中表名:
|
|
爆表字段信息:
|
|
爆字段内容信息:
|
|
综上,XPath函数报错的本质就是利用updatexml()和concat()两个函数,标准的语句就是
|
|
其中updatexml()是调用修改xml的功能,参数第一个和第三个随便填个数字(遵循其用法),第二个参数使用concat()函数拼接字符串,concat()的参数根据实际需要填写,个数不限,里面必须要有0x7e引起报错,结合查询参数,比如datebase()查数据库名,select语句(外面要加括号)查更详细内容。
extractvalue()函数
extractvalue()和updatexml()的用法基本一致,只不过extractvalue()只有两个参数,所以只需要删掉上面示例语句中updatexml()的第三个参数1就可以了。
例如:
|
|
方法二:count(*) + group by + floor(rand()*2)报错
原理解释(仅作了解)
前置知识:
1. rand(0) 的伪随机特性
rand(seed)是 伪随机数生成函数 ,当种子固定为0时,生成的随机数序列是完全固定的 。- 在同一个查询中 ,多次调用
rand(0)会生成连续的随机数(而非每次重置种子)。 - 实际测试序列(从种子
0开始):
| 调用次数 | rand(0)返回值 |
floor(rand(0)*2)结果 |
|---|---|---|
| 第 1 次 | 0.15522042769493574 | 0 |
| 第 2 次 | 0.6207181804390444 | 1 |
| 第 3 次 | 0.6387417590220086 | 1 |
| 第 4 次 | 0.4010441501938625 | 0 |
| 第 5 次 | 0.7180266582204114 | 1 |
2. GROUP BY 的虚拟表执行流程
GROUP BY会维护一个虚拟临时表 ,结构为(分组键x, 计数count),执行逻辑是:
- 初始化空虚拟表,分组键是唯一键(不允许重复)。
- 遍历原表每一行:a. 计算当前行的分组键表达式,得到
x1。b. 检查虚拟表是否存在x1:- 存在 → 对应行的
count加 1。 - 不存在 → 再次计算分组键表达式 得到
x2,然后插入新行(x2, 1)。
- 存在 → 对应行的
- 遍历结束后返回虚拟表结果。
按步骤还原报错过程:
假设users表有至少 3 行数据 (触发报错的必要条件),我们逐行分析虚拟表的变化:
初始化状态 ,虚拟表为空:
| x | count |
|---|---|
| 空 | 空 |
步骤 1:处理第 1 行数据
- 计算分组键 x1(第 1 次调用
rand(0)):floor(rand(0)*2) → 0。 - 检查虚拟表 :没有
x=0的行,需要插入新行。 - 再次计算分组键 x2 (第 2 次调用
rand(0)):floor(rand(0)*2) → 1。 - 插入虚拟表 :新增行
(1, 1)。
虚拟表现在:
| x | count |
|---|---|
| 1 | 1 |
步骤 2:处理第 2 行数据
- 计算分组键 x1 (第 3 次调用
rand(0)):floor(rand(0)*2) → 1。 - 检查虚拟表 :存在
x=1的行,将count加 1 →count=2。
虚拟表现在:
| x | count |
|---|---|
| 1 | 2 |
步骤 3:处理第 3 行数据(触发报错‼️)
- 计算分组键 x1 (第 4 次调用
rand(0)):floor(rand(0)*2) → 0。 - 检查虚拟表 :没有
x=0的行,需要插入新行。 - 再次计算分组键 x2 (第 5 次调用
rand(0)):floor(rand(0)*2) → 1。 - 尝试插入虚拟表 :新增行
(1, 1),但虚拟表中已存在**x=1**的行(分组键是唯一键)。 - 报错触发:MySQL 抛出
<font style="color:#DF2A3F;background-color:rgba(0, 0, 0, 0);">ERROR 1062 (23000): Duplicate entry '1' for key 'group_key'</font>(重复键错误)。
报错核心原因总结
- 双重计算分组键 :
GROUP BY在插入新行时会再次计算分组键,导致rand(0)被额外调用一次。 - 固定序列冲突 :
rand(0)的固定序列使得 “插入时计算的分组键” 与虚拟表中已存在的分组键重复。 - 唯一键约束 :虚拟表的分组键是唯一键,重复插入会触发主键冲突错误。
补充:如果users表行数不足 3,可能不会报错(比如仅 2 行时,插入 1 次后后续行直接累加计数,无二次插入)。
使用方法
示例payload:
爆当前数据库及表名:
|
|
爆当前表的所有字段名:
|
|
爆字段内容信息:
|
|
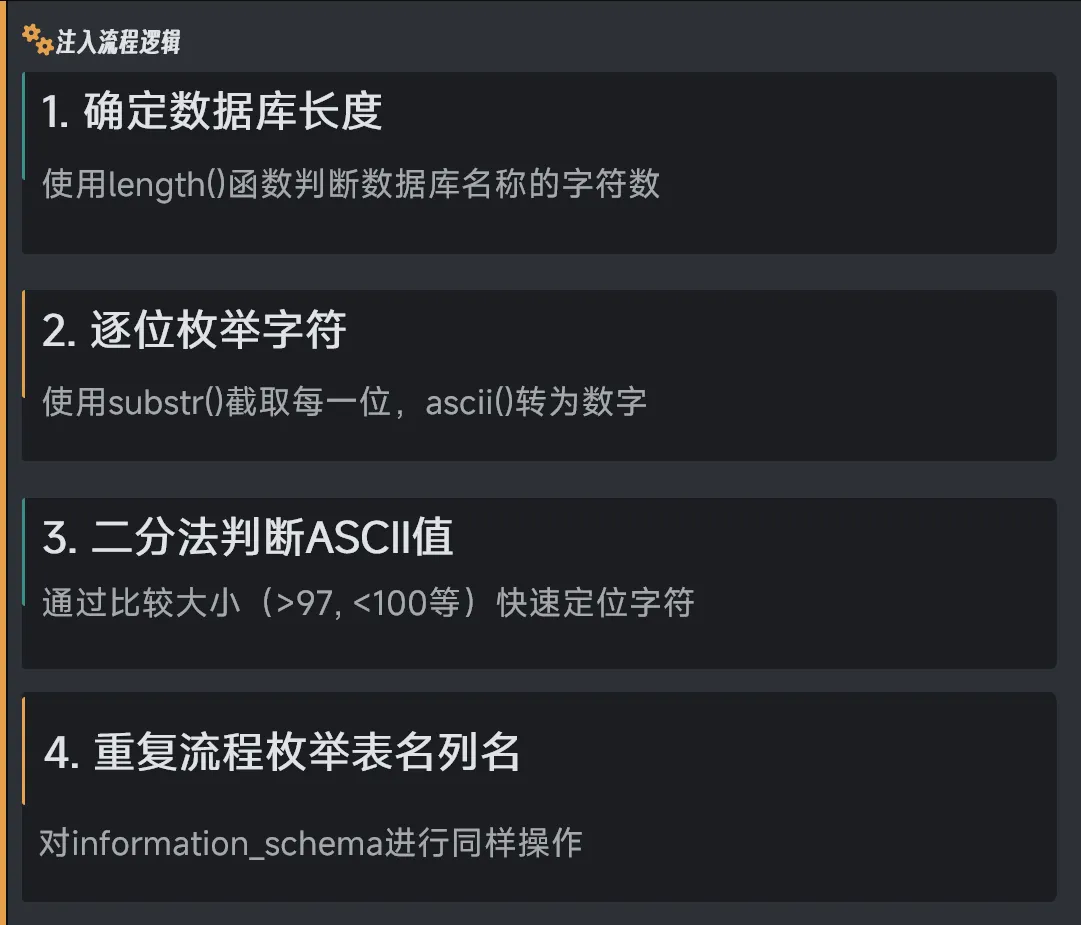
布尔型注入
构造不同的SQL语句,根据页面返回的真假状态(如页面正常显示、报错或空白)来逐位推断数据库信息。
适合无错误回显但页面有明显差异的场景。
核心函数
- length() - 判断长度
|
|
- substr() - 截取字符
|
|
- ascii() - 转ASCII码
|
|
💡效率优化: 使用二分法可大幅减少请求次数。ASCII值范围32-126,最多只需7次比较即可确定一个字符。
注意事项: 布尔型注入请求量大,易被WAF拦截。建议编写自动化脚本或使用SQLMap工具。
总之,了解原理就行,碰到就用sqlmap,别折磨自己。
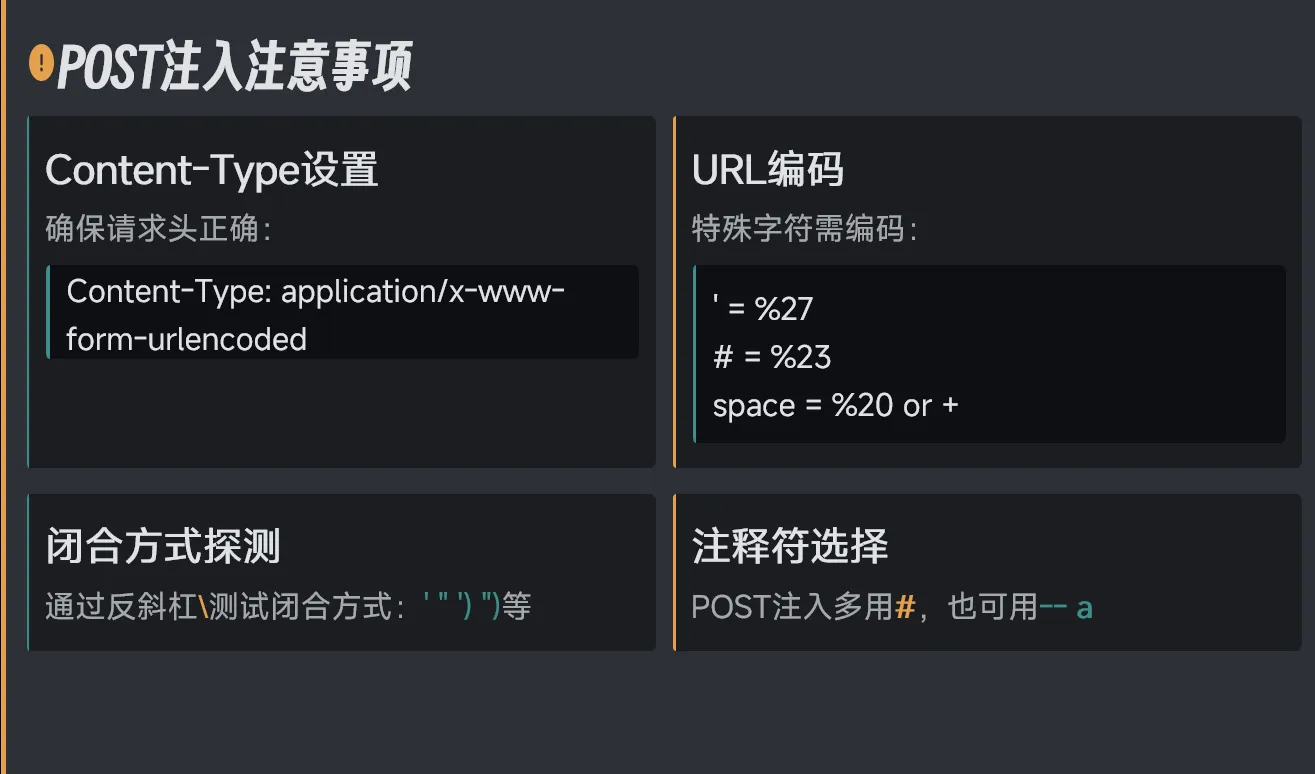
POST型盲注
之前我们接触的都是通过GET接收信息的类型,
但还存在通过POST接收信息的,通常存在于登录窗口等页面上
POST型盲注有这样几个特点
- 参数在请求体中
- 长度无限制
- 常用#注释
- 需抓包工具分析
小测验
第一关
在username一栏尝试闭合,发现admin'没有报错。
查看源码:
|
|
所以可以用万能钥匙绕过密码检查,username填admin' #即可
第二关
访问:[WeChall] Training: MySQL II
同样发现是单引号闭合。
查看源码:
|
|
发现这次是对用户名和密码单独进行校验,并且发现对密码进行了md5校验,因此唯一可操作的地方就是username,主要思路就是利用union select报错位掩盖真实数据来让程序以为自己查到的数据变成可以由我们指定的数据。
|
|
后面最大为3时不报错,说明存在3个报错位(也就是users这个表中的字段数)
根据常识字段大概依次为id,username,password,说明我们应该利用第2,3报错位,
根据题目要求username填admin,密码因为是md5加密过的,所以我们填
|
|
前面加-是为了引起报错,从而让后面的union select得以覆盖报错位。此外,使用or 1=2永假条件也可以强制报错。
第三关
访问:[WeChall] No Escape,我们的任务是修改任意一个候选人的票数为111,且程序提到票数达到100时会重制,所以靠手点肯定是不行的。
任意点击投票按钮发现网址后会跟着一个参数?vote_for=xxx
查看源码(核心):
|
|
可以看到是传入参数后用uodate函数将对应的值+1
已知句中第二个$who是我们传入的参数值,现在我们要使用闭合(注意原题使用反引号`闭合)加注释的方法在这一行进行注入。

上面的划线部分就是我们传入的参数,删除线部分是被注释掉的部分,从整个语句来看,该参数成功做到了将wagenk项对应的值修改为111,并且注释了后面原本的内容。所以此外还要注意POST数据的编码转换,所以最后的payload就是:
|
|
HTTP 头注盲注详解
基本概念
HTTP 头注盲注(HTTP Header Blind SQL Injection)是一种特殊的 SQL 注入攻击,攻击者通过篡改 HTTP 请求头部字段(如 User-Agent、Referer、Cookie、X-Forwarded-For 等),将恶意 SQL 代码注入到后端数据库查询中,同时由于应用程序不返回数据库错误信息或查询结果,只能通过页面响应差异(布尔值)或时间延迟来判断注入结果,从而逐位提取敏感数据的攻击方式。
漏洞原理
- 开发者将 HTTP 头信息直接写入数据库(如日志记录功能),未做过滤或转义处理
- 典型场景:
insert into logs(username, ip, useragent) values('admin', '127.0.0.1', 'user-agent内容'); - 全局过滤常只针对 GET/POST 参数,忽略 HTTP 头信息,导致绕过防御
常见注入点
HTTP 头中可能存在注入漏洞的字段包括:
| 头部字段 | 常见使用场景 | 注入风险说明 |
|---|---|---|
| User-Agent | 记录客户端浏览器信息 | 广泛用于日志,易被忽略过滤 |
| Referer | 记录访问来源页面 | 部分应用会存储该信息用于分析 |
| Cookie | 会话管理、用户标识 | 常包含用户 ID 等关键信息,直接用于查询 |
| X-Forwarded-For | 获取客户端真实 IP | 反向代理环境下常用,易被直接存入数据库 |
| Host | 指定目标服务器域名 | 部分应用会根据 Host 值生成动态内容 |
| Accept-Language | 语言偏好设置 | 多语言网站可能使用该值查询数据库 |
使用sqlmap注入
前置准备:抓取目标 HTTP 请求包
sqlmap 处理 HTTP 头注入时,最便捷的方式是先抓取完整的 HTTP 请求包并保存为文本文件(通常命名为request.txt)。
- 抓包工具 :Burp Suite
- 抓包示例 :
- 配置浏览器代理,拦截目标请求;
- 找到包含目标 HTTP 头(如 User-Agent、Cookie)的请求;
- 右键选择「Copy to file」保存为
request.txt。
- request.txt 示例内容 :
|
|
核心操作步骤
sqlmap 针对 HTTP 头注盲注的核心逻辑是:指定请求文件 → 标记注入点 → 选择盲注类型 → 自动化检测 / 提取数据。
基础命令(检测 HTTP 头注入漏洞)
指定单个 HTTP 头注入点
以User-Agent头为例,在请求文件中找到User-Agent行,在需要注入的位置添加*标记注入点,再执行 sqlmap 命令:
修改后的 request.txt (关键:User-Agent: *):
|
|
检测命令 :
|
|
针对 Cookie/Referer/X-Forwarded-For 等其他头
只需将*标记到对应头部字段即可,示例:
- Cookie 注入:
Cookie: PHPSESSID=* - X-Forwarded-For 注入:
X-Forwarded-For: * - Referer 注入:
Referer: *
如果 sqlmap 未自动识别盲注类型,可手动指定布尔盲注(B)或时间盲注(T):
布尔盲注(最常用)
|
|
时间盲注(无页面响应差异时)
|
|
提取数据
确认存在漏洞后,可通过在下面的基础命令上添加之前学习的参数提取数据库、表、字段、数据:
|
|
针对盲注速度慢的问题,可添加以下参数优化:
|
|