数据准备
资料获取
接下来的几个练习所用数据都在这里,请自行下载:
链接: https://pan.baidu.com/s/1b5ZZ5cVyS-9_06tql4tNFw 提取码: i3i6
分析文件
我们任选一个文件打开分析(此处以美国.txt为例)
文件大致为jsonp_1629344292311_69436({"status":0,"msg":"success" 。。。。。。32695,271457,169842]}]}}]});
发现此文件内容并不完全符合json格式,存在以下两点问题:
- 开头的花括号前多出来了
jsonp_1629344292311_69436(部分
- 结尾多了出了括号和分号
);
接下来为例便于查看json的层级结构,我们打开工具网站:JSON在线视图查看器(Online JSON Viewer)将上面文本中间去头去尾符合正确json格式的部分复制到左面的输入框,点击格式化按钮,这时右面已经出现了便于查看的结构树,如图:
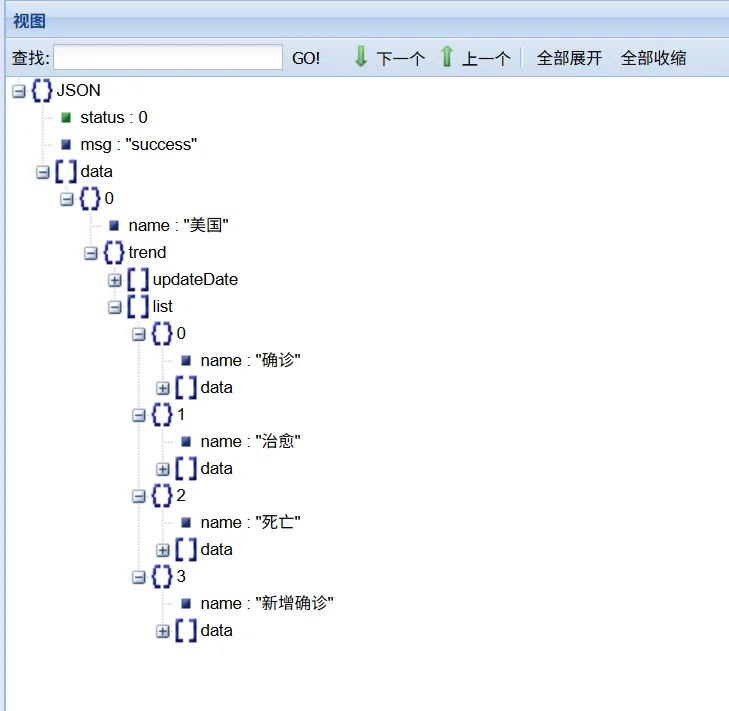
也可以参考下面给出的省略版:

总体可以看出其中,“update"中和下面的"data"中的数据应该具有对应关系
开始操作
为了方便演示,将三个国家分开操作,因此可以将任务总共分为下面几步:
- 打开并读取文件
- 去掉不合json规范的开头
- 去掉不合json规范的结尾
- json转python字典
- 获取trend key
- 获取日期数据,用于x轴,取2020年(到314下标结束)
- 获取确诊数据,用于y轴,取2020年(到314下标结束)
- 生成图表
分块演示
以美国.txt为例。
1
2
3
|
# 打开并读取文件
usdoc = open('T:/美国.txt','r',encoding='UTF-8')
us_data = usdoc.read()
|
打开美国.txt文件查看发现开头要删除的内容为:jsonp_1629344292311_69436(
根据前面所学的6.3 数据容器:字符串中2.2 节字符串的替换,我们这里使用replace()函数处理
1
|
us_data = us_data.replace('jsonp_1629344292311_69436(','')
|
接下来的结尾不能也用replace(),因为在文件中可能有多处出现了);,会出现多处替换的情况,因此我们使用字符串的切片,详见6.4 序列的操作:切片
下面导入json模块将字符串转为字典
1
2
|
import json
us_dict = json.loads(us_data)
|
下面回到浏览器,根据json视图一点点获取层级数据
1
|
us_trend = us_dict['data'][0]['trend']
|
目前剩下的结构
1
2
3
|
JSON
├─list(字典,格式为0:"2.22",1:"2.23")
└─updateDate
|
下面我们获取日期数据
1
|
us_x_data = us_trend['updateDate'][:314]
|
然后获取确诊数据
1
|
us_y_data = us_trend['list'][0]['data'][:314]
|
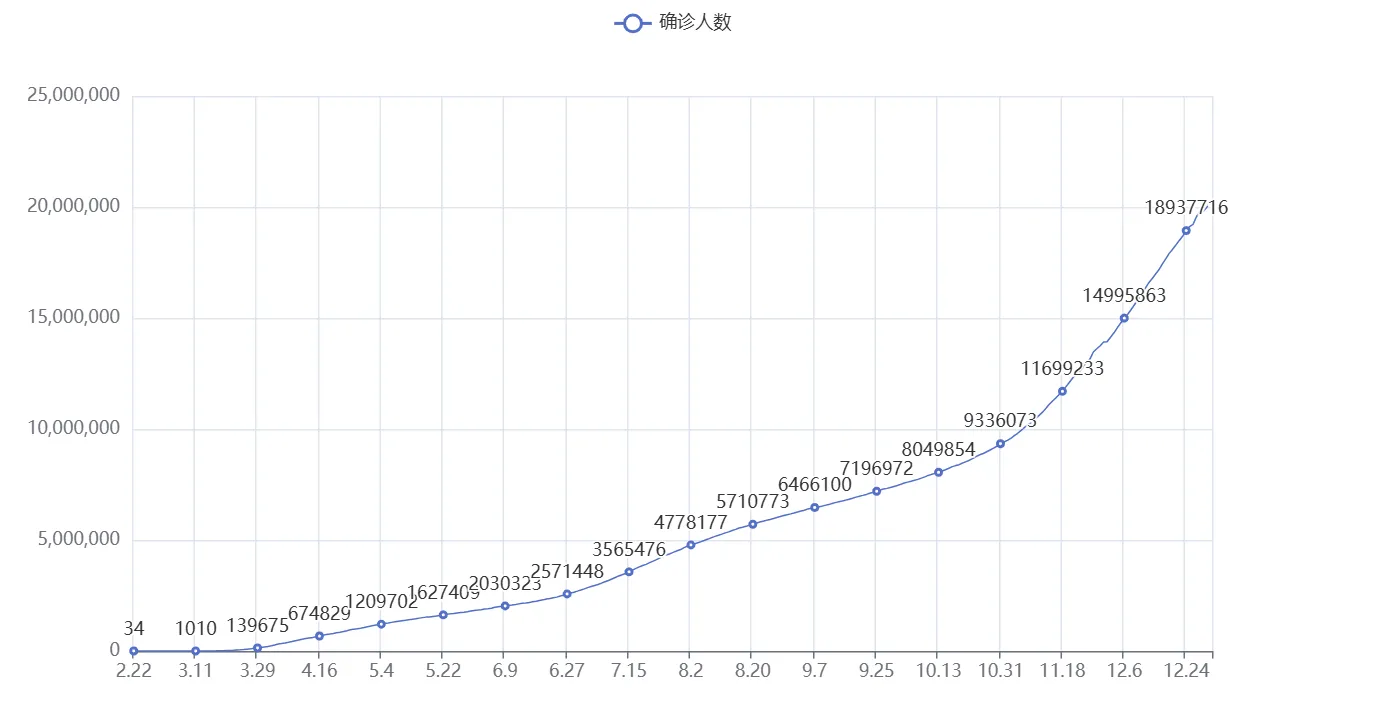
最后构建图表
1
2
3
4
5
6
7
8
9
10
|
# 导包,导入Line功能构建折线图对象
from pyecharts.charts import Line
# 得到折线图对象
line = Line()
# 添加x轴数据
line.add_xaxis(us_x_data)
# 添加y轴数据
line.add_yaxis("确诊人数", us_y_data)
# 生成图表
line.render()
|
单国完整版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import json
from pyecharts.charts import Line
usdoc = open('T:/美国.txt','r',encoding='UTF-8')
us_data = usdoc.read()
us_data = us_data.replace('jsonp_1629344292311_69436(','')
us_data = us_data[:-2]
us_dict = json.loads(us_data)
us_trend = us_dict['data'][0]['trend']
us_x_data = us_trend['updateDate'][:314]
us_y_data = us_trend['list'][0]['data'][:314]
line = Line()
line.add_xaxis(us_x_data)
line.add_yaxis("确诊人数", us_y_data)
line.render()
|
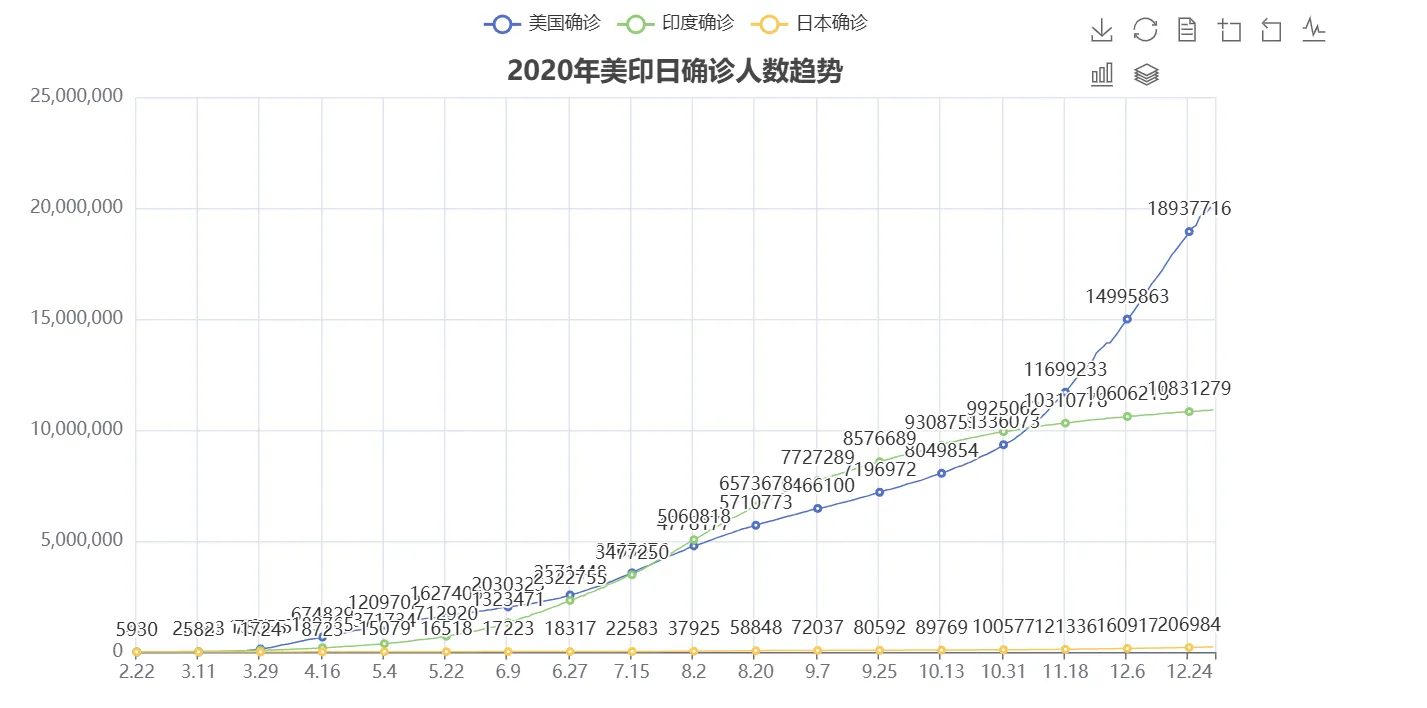
终极版(成品)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
import json
from pyecharts.charts import Line
from pyecharts.options import *
usdoc = open('T:/美国.txt','r',encoding='UTF-8')
indoc = open('T:/印度.txt','r',encoding='UTF-8')
jpdoc = open('T:/日本.txt','r',encoding='UTF-8')
us_data = usdoc.read()
in_data = indoc.read()
jp_data = jpdoc.read()
us_data = us_data.replace('jsonp_1629344292311_69436(','')
in_data = in_data.replace('jsonp_1629350745930_63180(','')
jp_data = jp_data.replace('jsonp_1629350871167_29498(','')
us_data = us_data[:-2]
in_data = in_data[:-2]
jp_data = jp_data[:-2]
us_dict = json.loads(us_data)
in_dict = json.loads(in_data)
jp_dict = json.loads(jp_data)
us_trend = us_dict['data'][0]['trend']
in_trend = in_dict['data'][0]['trend']
jp_trend = jp_dict['data'][0]['trend']
us_x_data = us_trend['updateDate'][:314]
us_y_data = us_trend['list'][0]['data'][:314]
in_y_data = in_trend['list'][0]['data'][:314]
jp_y_data = jp_trend['list'][0]['data'][:314]
line = Line()
line.add_xaxis(us_x_data)
line.add_yaxis("美国确诊", us_y_data)
line.add_yaxis("印度确诊", in_y_data)
line.add_yaxis("日本确诊", jp_y_data)
line.set_global_opts(
title_opts=TitleOpts(title="2020年美印日确诊人数趋势",pos_left="center",pos_top="1%"),
# 参数title设置标题文字,pos_left设置横向位置,pos_bottom设置距离底部位置
legend_opts=LegendOpts(is_show=True),
# 设置图例是否显示
toolbox_opts=ToolboxOpts(is_show=True),
# 设置工具箱是否显示
)
line.render()
|